
本题已收录至知乎圆桌:机器之能 X 语言之美,更多「人工智能」相关话题欢迎关注讨论。
中文分词是个基础问题,研究成果已有不少,我拣几个我自己觉得好的吧。
1. 好词典很重要
不论什么样的分词方法, 优秀的词典必不可少, 越拿老掉牙的词典对越新的文本进行分词, 就越会分成一团糟.
怎样构建一个优秀的词典, 快速发现新新词汇? 可以看 @M67 前两天写的文章, 讲的非常透彻明白 : 互联网时代的社会语言学:基于SNS的文本数据挖掘 ( http://www.matrix67.com/blog/archives/5044/trackback )
2. 算法跟着需求走
建议根据不同的需求选用不同的算法, 例如, 类似知乎头部搜索的 AutoComplete 部分, 讲究的是速度快, 兴趣相关( 优先找和你账户相关, 和可能感兴趣的内容 ), 分词算法反而在其次了. 而像全文搜索这样大段大段的长文字. 我觉得则更注重的是精准, 应该选一个像CRF这样的算法.
引用请注明来自:http://hi.baidu.com/fooying
四款python中文分词系统简单测试:
注:中科院分词可采用调用C库的方式使用
准确率测试(使用对应项目提供在线测试,未添加用户自定义词典)
结巴中文分词http://209.222.69.242:9000/
中科院分词系统http://ictclas.org/ictclas_demo.html
smallseghttps://smallseg.appspot.com/smallseg
snailseghttps://snailsegdemo.appspot.com/
(后两者网址需要翻墙)
测试文本1
工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作
测试结果:
结巴中文分词:
工信处/n 女干事/n 每月/r 经过/p 下属/v 科室/n 都/d 要/v 亲口/n 交代/n 24/m 口/q 交换机/n 等/u 技术性/n 器件/n 的/uj 安装/v 工作/vn
中科院分词系统:
工/n 信/n 处女/n 干事/n 每月/r 经过/p 下属/v 科室/n 都/d 要/v 亲口/d 交代/v 24/n 口/q 交换机/n 等/udeng 技术性/n 器件/n 的/ude1 安装/vn 工作/vn
smallseg:
工信 信处 女干事 每月 经过 下属 科室 都要 亲口 交代 24 口 交换机 等 技术性 器件 的 安装 工作
snailseg:
工信处/ 女/ 干事/ 每月/ 经过/ 下属/ 科室/ 都/ 要/ 亲口/ 交代/ 24/ 口/ 交换机/ 等/ 技术性/ 器件/ 的/ 安装/ 工作
-----------------------------------------------------------------------------------------
测试文本2
工信處女幹事每月經過下屬科室都要親口交代24口交換機等技術性器件的安裝工作
测试结果:
结巴中文分词:
工/n 信/n 處/zg 女/b 幹/zg 事/n 每月/r 經/zg 過/zg 下/m 屬/zg 科室/n 都/d 要/v 親/zg 口/q 交代/n 24/m 口交/n 換/zg 機/zg 等/u 技/ng 術/zg 性/ng 器件/n 的/uj 安/v 裝/zg 工作/vn
中科院分词系统:
工/n 信/n 處女/n 幹事/n 每月/r 經過/p 下屬/v 科室/n 都/d 要/v 親口/d 交代/v 24/n 口/q 交換機/n 等/udeng 技術性/n 器件/n 的/ude1 安裝/vn 工作/vn
smallseg:
工/ 信/ 處/ 女/ 幹/ 事/ 每月/ 經/ 過/ 下/ 屬/ 科室/ 都/ 要/ 親/ 口/ 交代/ 24/ 口/ 交/ 換/ / 機/ 等/ 技/ 術/ 性器/ 件/ 的/ 安/ 裝/ 工作
snailseg:
工/ 信/ 處/ 女/ 幹/ 事/ 每月/ 經/ 過/ 下/ 屬/ 科室/ 都/ 要/ 親/ 口/ 交代/ 24/ 口/ 交/ 換/ / 機/ 等/ 技/ 術/ 性器/ 件/ 的/ 安/ 裝/ 工作
-----------------------------------------------------------------------------------------
测试文本3
SCANV网址安全中心(http://scanv.com)是一个综合性的网址安全服务平台。通过网址安全中心,用户可以方便的查询到要访问的网址是否存在恶意行为,同时可以在SCANV中在线举报曝光违法恶意网站。
测试结果:
结巴中文分词:
SCANV/eng 网址/n 安全/an 中心/n scanv/eng com/eng 是/v 一个/m 综合性/n 的/uj 网址/n 安全/an 服务平台/n 通过/p 网址/n 安全/an 中心/n 用户/n 可以/c 方便/a 的/uj 查询/v 到/v 要/v 访问/v 的/uj 网址/n 是否/v 存在/v 恶意/v 行为/v 同时/c 可以/c 在/p SCANV/eng 中/f 在线/b 举报/v 曝光/nz 违法/vn 恶意/v 网站/n
中科院分词系统:
SCANV/x 网址/n 安全/an 中心/n (/wkz http://scanv.com/x )/wky 是/vshi 一个/mq 综合性/n 的/ude1 网址/n 安全/an 服务平台/n 。/wj 通过/p 网址/n 安全/an 中心/n ,/wd 用户/n 可以/v 方便/a 的/ude1 查询/vn 到/v 要/v 访问/v 的/ude1 网址/n 是否/v 存在/v 恶意/n 行为/n ,/wd 同时/c 可以/v 在/p SCANV/x 中/f 在/p 线/n 举报/vn 曝光/vn 违法/vn 恶意/n 网站/n 。/wj
smallseg:
SCANV 网址 安全 中心 http://scanv.com 是 一个 综合性 的 网址 安全 服务 平台 通过 网址 安全 中心 用户 可以 方便 的 查询 到要 访问 的 网址 是否 存在 恶意 行为 同时 可以 在 SCANV 中 在线 举报 曝光 违法 恶意 网站
snailseg:
SCANV/ 网址/ 安全/ 中心/ scanv/ com/ 是/ 一个/ 综合性/ 的/ 网址/ 安全/ 服务平台/ 通过/ 网址/ 安全/ 中心/ 用户/ 可以/ 方便/ 的/ 查询/ 到/ 要/ 访问/ 的/ 网址/ 是/ 否/ 存在/ 恶意/ 行为/ 同时/ 可以/ 在/ SCANV/ 中/ 在/ 线/ 举报/ 曝光/ 违法/ 恶意/ 网站
-----------------------------------------------------------------------------------------
测试文本4
随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。总会有一些功能是需要调用本地存档的。例如登录模块中,记住密码功能,会将密码信息存储在本地,以IE浏览器为例,在C:\\Documents and Settings\\(你的Windows用户名)\\Application Data\\Macromedia \\Flash Player\\#SharedObjects\\(一些随机数字和字母)\\ 文件夹下就可以看到存储密码的SOL文件,可以使用minerva工具查看,如下图所示,密码明文明文存储的,SOL文件是永久性保存的,除非手动清除,如果玩家在公共环境下登录,就会有盗号威胁。来自http://www.baidu.com/及http:、www.baidu...com
测试结果:
结巴中文分词:
随着/p 页/m 游/n 兴起/v 到/v 现在/t 的/uj 页游/n 繁盛/a 依赖于/v 存档/v 进行/v 逻辑/n 判断/v 的/uj 设计/vn 减少/v 了/ul 但/c 这块/r 也/d 不能/v 完全/ad 忽略/d 掉/zg 总会/n 有/v 一些/m 功能/n 是/v 需要/v 调用/vn 本地/r 存档/v 的/uj 例如/v 登录/v 模块/n 中/f 记住/v 密码/n 功能/n 会/v 将/d 密码/n 信息/n 存储/j 在/p 本地/r 以/p IE/eng 浏览器/n 为/p 例/v 在/p C/eng Documents/eng and/eng Settings/eng 你/r 的/uj Windows/eng 用户名/n Application/eng Data/eng Macromedia/eng nbsp/eng Flash/eng Player/eng #SharedObjects/eng 一些/m 随机/d 数字/n 和/c 字母/n 文件夹/n 下/f 就/d 可以/c 看到/v 存储/j 密码/n 的/uj SOL/eng 文件/n 可以/c 使用/v minerva/eng 工具/n 查看/v 如下/t 图/n 所示/v 密码/n 明文/nr 明文/nr 存储/j 的/uj SOL/eng 文件/n 是/v 永久性/nr 保存/v 的/uj 除非/c 手动/n 清除/v 如果/c 玩家/n 在/p 公共/b 环境/n 下/f 登录/v 就/d 会/v 有/v 盗号/n 威胁/vn 来自/v http/eng www/eng baidu/eng com/eng 及/c http/eng www/eng baidu/eng com/eng
中科院分词系统:
随着/p 页/q 游兴/n 起/vf 到/v 现在/t 的/ude1 页/q 游/v 繁盛/an ,/wd 依赖/v 于/p 存档/vi 进行/vx 逻辑/n 判断/v 的/ude1 设计/vn 减少/v 了/y ,/wd 但/c 这/rzv 块/q 也/d 不能/v 完全/ad 忽略/v 掉/v 。/wj 总/d 会/v 有/vyou 一些/mq 功能/n 是/vshi 需要/v 调用/v 本地/rzs 存档/vi 的/ude1 。/wj 例如/v 登录/v 模块/n 中/f ,/wd 记住/v 密码/n 功能/n ,/wd 会/v 将/p 密码信息存储/n 在/p 本地/rzs ,/wd 以/p IE/x 浏览器/n 为/p 例/n ,/wd 在/p C:/x \/x Documents/x /w and/x /w Settings/x \/x (/wkz 你/rr 的/ude1 Windows/x 用户/n 名/q )/wky \/x Application/x /w Data/x \/x Macromedia/x &/x nbsp/x ;/wf \/x Flash/x /w Player/x \/x #/x SharedObjects/x \/x (/wkz 一些/mq 随机/b 数字/n 和/cc 字母/n )/wky \/x /w 文件夹/n 下/f 就/d 可以/v 看到/v 存储/vn 密码/n 的/ude1 SOL/x 文件/n ,/wd 可以/v 使用/v minerva/x 工具/n 查看/v ,/wd 如/v 下/vf 图/n 所/usuo 示/vg ,/wd 密码/n 明/ag 文明/n 文/ng 存储/v 的/ude1 ,/wd SOL/x 文件/n 是/vshi 永久性/n 保存/v 的/ude1 ,/wd 除非/c 手动/b 清除/vn ,/wd 如果/c 玩/v 家/n 在/p 公共/b 环境/n 下/f 登录/v ,/wd 就/d 会/v 有/vyou 盗/vg 号/n 威胁/vn 。/wj 来自/v http:/x //w //w http://www.baidu.com/x //w 及/v http:/x 、/wn www.baidu...com/x
smallseg:
随着 页游 兴起 到现在 的页 页游 繁盛 依赖于 存档 进行 逻辑 判断 的 设计 减 少了 但 这块 也 不能 完全 忽略 掉 总 会有 一些 功能 是 需要 调用 本地 存档 的 例如 登录 模块 中 记住 密码 功能 会将 密码 信息 存储 在 本地 以 IE 浏览器 为例 在 C \\ Documents and Settings \\ 你的 Windows 用户名 \\ Application Data \\ Macromedia & nbsp ;\\ Flash Player \\ #SharedObjects \\ 一些 随机 数字 和 字母 \\ 文件夹 下 就可 以 看到 存储 密码 的 SOL 文件 可 以 使用 minerva 工具 查看 如 下图 所示 密码 明文 明文 存储 的 SOL 文件 是 永久性 保存 的 除非 手动 清除 如果 玩家 在 公共 环境 下 登录 就会 有 盗号 威胁 来自 http // http://www.baidu.com /及 http www.baidu...com
snailseg:
随着/ 页/ 游兴/ 起到/ 现在/ 的/ 页/ 游/ 繁盛/ 依赖/ 于/ 存档/ 进行/ 逻辑/ 判断/ 的/ 设计/ 减少/ 了/ 但/ 这/ 块/ 也/ 不能/ 完全/ 忽略/ 掉/ 总会/ 有/ 一些/ 功能/ 是/ 需要/ 调用/ 本地/ 存档/ 的/ 例如/ 登录/ 模块/ 中/ 记住/ 密码/ 功能/ 会/ 将/ 密码/ 信息/ 存储/ 在/ 本地/ 以/ IE/ 浏览器/ 为/ 例/ 在/ C/ Documents/ and/ Settings/ 你/ 的/ Windows/ 用户名/ Application/ Data/ Macromedia/ nbsp/ Flash/ Player/ #SharedObjects/ 一些/ 随机数/ 字/ 和/ 字母/ 文件/ 夹/ 下/ 就/ 可以/ 看到/ 存储/ 密码/ 的/ SOL/ 文件/ 可以/ 使用/ minerva/ 工具/ 查看/ 如下/ 图/ 所/ 示/ 密码/ 明文/ 明文/ 存储/ 的/ SOL/ 文件/ 是/ 永久性/ 保存/ 的/ 除非/ 手动/ 清除/ 如果/ 玩家/ 在/ 公共/ 环境/ 下/ 登录/ 就/ 会/ 有/ 盗/ 号/ 威胁/ 来/ 自/ http/ www/ baidu/ com/ 及/ http/ www/ baidu/ com
结论:从整体测试结果上看,分词速度以及文本超过一定长度的性能测试未进行,自定义词典也是一个很大的影响分词因素,也未涵盖测试,排除以上两点,整体上看,对繁体以及网址的分词,中科院的分词系统做到最好,如果论说对容易歧义的文本,结巴不错,这两者也相对功能方面会更丰富。感觉如果python分词,建议使用结巴或者中科院分词调用C库使用,如果担心调用C库等产生的相关问题,可以使用结巴分词系统,是个不错的选择,在分词前进行简繁转换;或者采用中科院的分词,加上自定义词典,也是不错的选择,不过就本人在python调用C库使用中科院分词的过程中,存在用户自定义词典导入会过于优先(如导入用户词典,中信,当分词内容[我们中信仰佛教的人]会分词成[我们,中信,仰,佛教,的,人])以及存在导入失败情况,还有函数调用安全问题。主要是根据需要进行选择不同的分词。有空再进行性能测试!
欢迎使用我们组推出的THULAC工具包,包括中文分词和词性标注功能,现在有C++、Java和Python版本供选择:
THULAC:一个高效的中文词法分析工具包该页面有THULAC与主流分词工具的定量比较。
THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。THULAC具有如下几个特点:
能力强。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
准确率高。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。
速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到1.3MB/s。
中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块。不同于英文的是,中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词,分词效果将直接影响词性、句法树等模块的效果。当然分词只是一个工具,场景不同,要求也不同。
在人机自然语言交互中,成熟的中文分词算法能够达到更好的自然语言处理效果,帮助计算机理解复杂的中文语言。竹间智能在构建中文自然语言对话系统时,结合语言学不断优化,训练出了一套具有较好分词效果的算法模型,为机器更好地理解中文自然语言奠定了基础。
在此,对于中文分词方案、当前分词器存在的问题,以及中文分词需要考虑的因素及相关资源,竹间智能 自然语言与深度学习小组 做了些整理和总结,希望能为大家提供一些参考。
中文分词根据实现原理和特点,主要分为以下2个类别:
1、基于词典分词算法
也称字符串匹配分词算法。该算法是按照一定的策略将待匹配的字符串和一个已建立好的“充分大的”词典中的词进行匹配,若找到某个词条,则说明匹配成功,识别了该词。常见的基于词典的分词算法分为以下几种:正向最大匹配法、逆向最大匹配法和双向匹配分词法等。
基于词典的分词算法是应用最广泛、分词速度最快的。很长一段时间内研究者都在对基于字符串匹配方法进行优化,比如最大长度设定、字符串存储和查找方式以及对于词表的组织结构,比如采用TRIE索引树、哈希索引等。
2、基于统计的机器学习算法
这类目前常用的是算法是HMM、CRF、SVM、深度学习等算法,比如stanford、Hanlp分词工具是基于CRF算法。以CRF为例,基本思路是对汉字进行标注训练,不仅考虑了词语出现的频率,还考虑上下文,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。
Nianwen Xue在其论文《Combining Classifiers for Chinese Word Segmentation》中首次提出对每个字符进行标注,通过机器学习算法训练分类器进行分词,在论文《Chinese word segmentation as character tagging》中较为详细地阐述了基于字标注的分词法。
常见的分词器都是使用机器学习算法和词典相结合,一方面能够提高分词准确率,另一方面能够改善领域适应性。
随着深度学习的兴起,也出现了基于神经网络的分词器,例如有人员尝试使用双向LSTM+CRF实现分词器,其本质上是序列标注,所以有通用性,命名实体识别等都可以使用该模型,据报道其分词器字符准确率可高达97.5%。算法框架的思路与论文《Neural Architectures for Named Entity Recognition》类似,利用该框架可以实现中文分词,如下图所示:
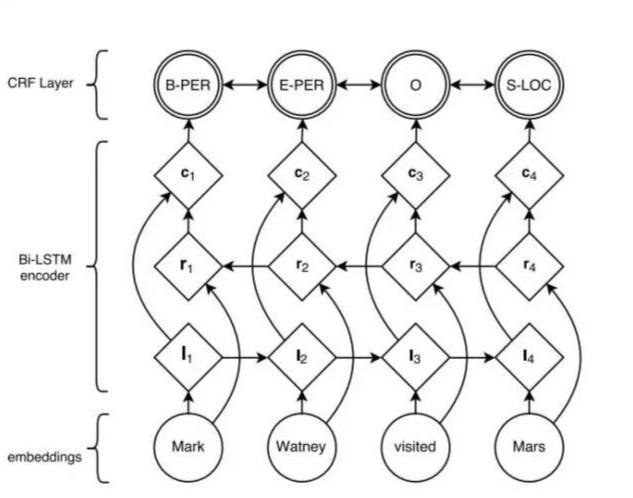
首先对语料进行字符嵌入,将得到的特征输入给双向LSTM,然后加一个CRF就得到标注结果。
分词器当前存在问题:
目前中文分词难点主要有三个:
1、分词标准:比如人名,在哈工大的标准中姓和名是分开的,但在Hanlp中是合在一起的。这需要根据不同的需求制定不同的分词标准。
2、歧义:对同一个待切分字符串存在多个分词结果。
歧义又分为组合型歧义、交集型歧义和真歧义三种类型。
1) 组合型歧义:分词是有不同的粒度的,指某个词条中的一部分也可以切分为一个独立的词条。比如“中华人民共和国”,粗粒度的分词就是“中华人民共和国”,细粒度的分词可能是“中华/人民/共和国”
2) 交集型歧义:在“郑州天和服装厂”中,“天和”是厂名,是一个专有词,“和服”也是一个词,它们共用了“和”字。
3) 真歧义:本身的语法和语义都没有问题, 即便采用人工切分也会产生同样的歧义,只有通过上下文的语义环境才能给出正确的切分结果。例如:对于句子“美国会通过对台售武法案”,既可以切分成“美国/会/通过对台售武法案”,又可以切分成“美/国会/通过对台售武法案”。
一般在搜索引擎中,构建索引时和查询时会使用不同的分词算法。常用的方案是,在索引的时候使用细粒度的分词以保证召回,在查询的时候使用粗粒度的分词以保证精度。
3、新词:也称未被词典收录的词,该问题的解决依赖于人们对分词技术和汉语语言结构的进一步认识。
另外,我们收集了如下部分分词工具,供参考:
中科院计算所NLPIR http://ictclas.nlpir.org/nlpir/
ansj分词器 https://github.com/NLPchina/ansj_seg
哈工大的LTP https://github.com/HIT-SCIR/ltp
清华大学THULAC https://github.com/thunlp/THULAC
斯坦福分词器 https://nlp.stanford.edu/software/segmenter.shtml
Hanlp分词器 https://github.com/hankcs/HanLP
结巴分词 https://github.com/yanyiwu/cppjieba
KCWS分词器(字嵌入+Bi-LSTM+CRF) https://github.com/koth/kcws
ZPar https://github.com/frcchang/zpar/releases
IKAnalyzer https://github.com/wks/ik-analyzer
以及部分分词器的简单说明:
哈工大的分词器:主页上给过调用接口,每秒请求的次数有限制。
清华大学THULAC:目前已经有Java、Python和C++版本,并且代码开源。
斯坦福分词器:作为众多斯坦福自然语言处理中的一个包,目前最新版本3.7.0, Java实现的CRF算法。可以直接使用训练好的模型,也提供训练模型接口。
Hanlp分词:求解的是最短路径。优点:开源、有人维护、可以解答。原始模型用的训练语料是人民日报的语料,当然如果你有足够的语料也可以自己训练。
结巴分词工具:基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG);采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
字嵌入+Bi-LSTM+CRF分词器:本质上是序列标注,这个分词器用人民日报的80万语料,据说按照字符正确率评估标准能达到97.5%的准确率,各位感兴趣可以去看看。
ZPar分词器:新加坡科技设计大学开发的中文分词器,包括分词、词性标注和Parser,支持多语言,据说效果是公开的分词器中最好的,C++语言编写。
关于速度:
由于分词是基础组件,其性能也是关键的考量因素。通常,分词速度跟系统的软硬件环境有相关外,还与词典的结构设计和算法复杂度相关。比如我们之前跑过字嵌入+Bi-LSTM+CRF分词器,其速度相对较慢。另外,开源项目 https://github.com/ysc/cws_evaluation 曾对多款分词器速度和效果进行过对比,可供大家参考。
最后附上公开的分词数据集
测试数据集
1、SIGHAN Bakeoff 2005 MSR,560KB
http://sighan.cs.uchicago.edu/bakeoff2005/
2、SIGHAN Bakeoff 2005 PKU, 510KB
http://sighan.cs.uchicago.edu/bakeoff2005/
3、人民日报 2014, 65MB
https://pan.baidu.com/s/1hq3KKXe
本回答来自 竹间智能 自然语言与深度学习小组 。
电话:13988888888
传 真:海南省海口市
手 机:0898-66889888
邮 箱:88889999
地 址:/public/upload/system/2018/07/28/2091301cca30ff8c6fd3ecd09c8d4b02.jpg

